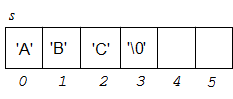
Памяти под неё отведём 6 байт, поэтому описание будет следующим:
В языках С/С++ имеются большие возможности по обработке символьной информации. Здесь приведён только тот материал, который является общим для этих языков. Позже, при изучении стандартных классов, рассмотрим ещё и класс string, имеющийся только в С++.
Для представления символов в памяти компьютера используется тип char. Можно в качестве примера привести определение констант и переменных этого типа:
const char c1 = 'A';// константная переменная
char c = c1, c2; // переменные
Под данные типа char отводится 1 байт. Тип char является целым типом, поэтому внутреннее представление для данных типа char (их коды) — это просто целые числа.
Для кодировки символов используется ASCII-код (American Standard Code for Information Interchange — американский стандартный код для обмена информацией). Это семибитный код, позволяющий записать 128 различных комбинаций (знаков). Так как под данные типа char отводится 8 двоичных цифр (бит), то имеется возможность закодировать ещё 128 знаков. Таким образом, кодовая таблица состоит из двух частей: младшая — соответствует ASCII-код, старшая — используется для представления национальных шрифтов, символов псевдографики и прочее.
Для различных систем кодировок младшая часть кодовой таблицы всегда одинакова, а старшая может быть различной. В нашей стране сейчас наиболее популярной является Windows-кодировка (Кодовая таблица 1251), для совместимости со старыми программами применяется DOS-кодировка (Кодовая таблица 866), а при работе в операционной системе Linux довольно распространена кодировка KOI8-R.
Для работы с данными типа char можно использовать все арифметические операции, операции сравнения и побитовые операции, хотя, если учесть, что этот тип используется для представления не чисел, а именно символов, то, естественно, чаще всего применяют операции сравнения.
В языках С/С++ имеется большое количество стандартных функций. Приведём некоторые из них. Пусть в программе дано описание следующих переменных:
char c;
int k;
Тогда можно в качестве примеров вызова стандартных функций для работы с символьной информацией написать следующее:
1)чтение одного символа из стандартного устройство ввода (обычно это клавиатура):
c = getchar();
2)чтение одного символа из файла (здесь f — указатель на структуру FILE, предопределённую в языках С/С++):
c=fgetc(f);
Работу с файлами будем рассматривать немного позже, а пока можно применить такой вариант этой же функции:
c=fgetc(stdin);
где stdin — идентификатор стандартного устройства ввода (это имя предопределёно для С/С++).
3)вывод символа на стандартное устройство вывода (обычно это дисплей монитора):
putchar(c);
4)вывод одного символа в файл (здесь f — указатель на структуру FILE):
fputc(c,f);
Для вывода на стандартное устройство вывода (идентификатор stdout также предопределён для С/С++) можно записать так:
fputc(c,stdout);
5)проверка того, что символ — латинская буква:
k=isalpha(c);
Здесь k будет не равно 0, если в переменой c хранится символ — латинская буква, и равно 0 — в противном случае.
6)проверка того, что символ — это цифра:
k=isdigit(c);
Результат — не 0, если в c находится символ цифры, и 0 — если это не так.
В языках С/С++ нет встроенного строкового типа данных. Для работы со строками используется массив данных типа char. Но это не обычный массив! Если подразумевается, что работа ведётся не просто с массивом символов, а со строкой, то она должна заканчиваться символом с кодом 0 ('\0' — нуль-символ). Именно нуль-символ показывает, где заканчиваются данные в таком массиве.
Пусть дана строка s (см. рисунок):
Памяти
под неё отведём 6
байт, поэтому описание будет следующим:
char s[6];
Полезная информация (текст "ABC") размещается в первых трёх байтах, а затем в третьем байте находится нуль-символ '\0'.
Строку s можно было бы инициализировать, т.е. на этапе компиляции задать ей начальное значение:
char s[6] = {'A', 'B', 'C', '\0'};
Так как s — это массив (хотя и символов), поэтому инициализация записана точно так же, как это обычно делается для массива. Но s — это ещё и строка, поэтому допускается упрощённый вариант инициализации, схожий с инициализацией простых переменных:
char s[6] = "ABC";
Такой вариант проще и для записи, и для понимания. Обычно им все и пользуются.
При инициализации для строки допустимо не задавать объём выделяемой памяти:
char s[] = "ABC";
Теперь компилятор сам подсчитает, сколько требуется отвести памяти под строку, и выделит под неё необходимый объём.
Когда память под строку выделена, с этой строкой можно начинать работать. Строки — весьма своеобразные объекты. С одной стороны — это массивы, поэтому можно обращаться по индексу к нужной ячейке, изменять содержимое этой ячейки, например:
s[1]='i';
В итоге строка "ABC" превратится в "AiC".
С другой стороны, работа со строкой похожа на работу с простой переменной, например, вывод строки на экран монитора (используем стандартную операцию вывода языка С++):
cout << "s=" << s << endl;
Согласитесь, что это гораздо проще, чем вывод на экран монитора массива чисел, где требовался цикл:
for(i = 0; i < n; i++)
cout << x[i] << endl;
1.Вывод строки на экран монитора
1а)Используем стандартную операцию вывода языка С++:
cout << "s=" << s << endl;
1б)Используем функцию вывода на экран символьной строки (функция языка С):
puts(s);
2.Ввод строки так же прост, но имеются некоторые "подводные камни". Рассмотрим варианты.
2а)Используем стандартную операцию ввода языка С++:
cin >> s;
Таким способом можно прочитать со стандартного устройства только строку без пробелов, так как при использовании операции ввода (>>) именно пробел является разделителем, что позволяет последовательно считать данные в две или более переменные, например:
int a,b;
cin >> a >> b;
2б)Ввод строки, содержащей пробелы:
gets(s);
где gets() — стандартная функция чтения строки, вводимой с клавиатуры. Читается любая информация до нажатия клавиши "Enter". Символы конца ввода (их коды — это десятичные числа 13 (возврат каретки) и 10 (перевод строки)) заменяются на нуль-символ.
Всё вроде бы хорошо, но здесь нет проверки на количество введённой информации. Если памяти под строку s отведено 6 байт (как на рисунке выше), то ввод более, чем 5 символов создаст проблему. Языки С/С++ не контролируют выход за пределы массива, поэтому введённая информация может попасть на соседние участки памяти. Решением проблемы может стать следующий вариант.
2в)Чтение строки из файла:
fgets(s, n, f);
где fgets() — функция чтения в строку s не более, чем n-1 символов из файла f. В этом случае ввод будет закончен либо по достижению конца файла, либо по ограничению на количество вводимых символов. В строку s также будет добавлен нуль-символ.
Так как нам нужен ввод не из файла как такового, а со стандартного устройства ввода (клавиатуры), то применим следующий вариант:
fgets(s, n, stdin);
Здесь ввод строки будет завершён либо по нажатию на клавишу "Enter", либо по ограничению на длину строки. В строку также будет добавлен нуль-символ. Именно этим вариантом и нужно пользоваться для ввода с клавиатуры или для чтения из файла строк, в которых могут быть пробелы.
Но и на этом проблемы не заканчиваются. Дело в том, что функция fgets() имеет побочный эффект. Кроме полезной информации, что была набрана с клавиатуры, в конец строки будет помещён символ с кодом 10, а только затем символ с кодом 0. Для каких-то задач это не существенно, но лучше всегда удалять этот "мусор": в позицию символа с кодом 10 записывать нуль-символ.
Корректный способ использования fgets():
fgets(s, n, stdin);
int k = strlen(s); // Длина строки
if((k > 0) && (s[k-1] == 10))
{
k--;
s[k] = '\0';
}
Если же строка считывается из файла, а не вводится с клавиатуры, то этот побочный эффект может проявляться, а может и не проявляться. Например, набираем в программе "Блокнот" последовательность знаков
ABC
Курсор остался сразу же за символом 'C'. Затем сохраняем текст в файле. Здесь нет лишних знаков, поэтому ни какого побочного эффекта не будет. Но стоит только после набранной в текстовом редакторе строки нажать клавишу "Enter", то получится файл с текстом, при чтении из которого будет то же "счастье", что и при вводе с клавиатуры. Поэтому при чтении из файла строки, содержащей пробелы, надо использовать те же проверки, что и при вводе с клавиатуры, если пользуемся функцией fgets().
3.Вычисление длины строки:
int k;
k = strlen(s);
здесь k — это текущая длина строки, то есть количество полезной информации (формально — количество элементов до нуль-символа). К примеру, для строки
char s[6] = "ABC";
k будет равно 3.
4.Объём памяти, отведенной под строку, можно вычислить по формуле:
int size = sizeof(s)/sizeof(char);
5.Сцепление строк (конкатенация)
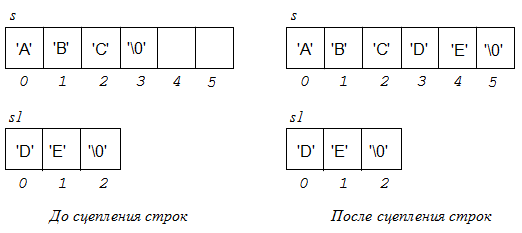
strcat(s, s1);
Здесь в конец строки s добавляется содержимое строки s1. Результат сохраняется в строке s. Строка s1 не изменяется.
6.Копирование строк:
strcpy(s, s1);
Данные из строки s1 побайтно копируются в строку s. Прежнее содержание строки s теряется, а строка s1 остаётся неизменной.
7.Сравнение строк:
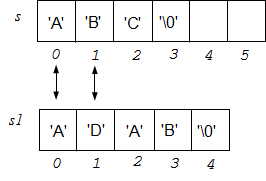
char s[6] = "ABC";
char s1[] = "ADAB";
int k = strcmp(s, s1);
В функции strcmp() выполняется побайтное сравнение кодов символов: s[0] и s1[0] равны — идём дальше; s[1] и s1[1] — не равны, код символа 'D' больше кода 'B', следовательно строка s1 больше s.
Результат работы функции:
k = 0 — строки равны;
k < 0 — строка s меньше s1;
k > 0 — строка s больше s1.
8.Поиск первого вхождения символа в строке:
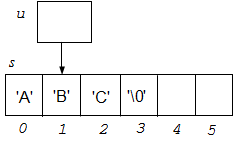
char *u;
char c = 'B';
u = strchr(s, c);
Результатам выполнения функции strchr() будет адрес первого символа в строке s, который равен искомому символу c. Если символ не найден, то в указатель u будет записано число 0.
9.Поиск первого вхождения подстроки в исходной строке:
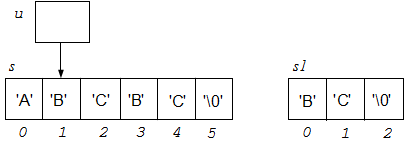
u = strstr(s, s1);
Здесь в строке s подстрока "BC" встречается дважды, но в указатель u будет записан адрес первой из них (с индекса, равного 1).
Замечание по работе со строками
1)Если длина строки изменяется не стандартными функциями типа strcat() или strcpy(), а средствами пользователями, то необходимо самому добавлять в конец строки нуль-символ.
Пример:
char s[6];
int i;
for(i = 0; i < 4; i++)
s[i] = i + 'A';
s[i]='\0';
Заполняем s символьной строкой "ABCD". После выхода из цикла переменная i равна 4. В эту позицию и записываем нуль-символ.
2)Если в памяти исходные строки пересекаются, то для ряда функций, таких, как копирование, сцепление, возможны побочные эффекты, и результат работы функций не предсказуем.
3)В этой теме приведены примеры использования только некоторых функций по работе со строками. Существует целый ряд функций, позволяющих обработать только часть строки, например:
int n1=2;
strncat(s, s1, n1);
Добавить в конец строки s первые n1 символов из строки s1. В таких функциях (strncat(), strncmp() и другие) в середине названия записан символ n.
Обычно обработка ведётся с начала строки, но есть варианты функций для обработки строк с конца, например:
char *u;
char c = 'B';
u = strrchr(s, c);
Вычисляется адрес последнего вхождения символа c в строку s. Здесь в середине названия функции (strrchr()) присутствует символ r (сокращение слова right — правый).
4)Для обработки строк необходимо подключать заголовочный файл
#include <string.h>
который обеспечивает доступ к прототипам всех необходимых функций по работе со строками.
5)Если применяются функции чтения-записи символов (getchar(), putchar()) или строк (gets(), fgets(), puts()), то необходимо подключать заголовочный файл
#include <stdio.h>
Работая со строками, необходимо придерживаться простых правил:
везде, где есть такая возможность, используем стандартные функции по обработке строк;
если нет подходящей стандартной функции — работаем со строкой как с массивом;
не забываем о нуль-символе в конце строки.
Пример 1. Дана символьная строка, не содержащая пробелов. Заменить все символы '+', расположенные за первой буквой 'A', на символы '*'.
Возможный вариант реализации:
#include <iostream>
using namespace std;
#include <string.h>
#include <stdio.h>
int main()
{
char s[30];
cout << "Input s:" << endl;
cin >> s;
char *u = strchr(s,'A');
if(u)
{
u++;
for(int i=0; i < strlen(u); i++)
if(u[i] == '+')
u[i] = '*';
}
cout <<"s=" << s << endl;
return 0;
}
Пример 2. Дана символьная строка. Подсчитать количество слов, из которых состоит эта строка. Под понятием «слово» будем подразумевать последовательность любых вводимых с клавиатуры (или из текстового файла) символов, разделённых одним или несколькими пробелами.
Возможный вариант реализации:
#include <iostream>
using namespace std;
#include <string.h>
#include <stdio.h>
int main()
{
char s[80];
cout << "Input s:" << endl;
gets(s);
int i, d = strlen(s), k = 0;
if(d > 0)
{
for(i = 0; i < d - 1; i++)
if(s[i] != ' ' && s[i+1] == ' ')
k++;
if(s[d-1] != ' ')
k++;
}
cout <<"k=" << k << endl;
return 0;
}
|
|
|
|